RSSGuard without RSS: scraping with CSS selectors
Despite the modern internet’s tendency to centralise towards a small number of big content gateways (Reddit, Twitter, Hacker News etc), I still like the feeling of independence and self-directed deliberateness that comes with RSS. Rather than just stepping into the firehose of what the latest "Big Tech" recommender systems want to show me, it’s me deciding who I want to hear more from.
These days I use RSSGuard, a very simple and lightweight reader for RSS/ATOM/JSON feeds.
However, many interesting sites do not provide any kind of syndication feed. There is an online service called RSS Everything that will accept a website URL and some filters (to narrow down the section of the page you’re interested in watching for changes), and gives you an RSS feed URL that presents the data periodically scraped from that page. The filters seem to be based on a stripped-down regex, though, which is not sufficient for parsing HTML.
There are probably other sites and self-hosted tools that can do this, but I found a nice way that works with RSS Guard. After reading the docs, I was pointed to a handy little Python utility called CSS2RSS. This takes HTML source via standard input and a CSS selector for the relevant part of the page, then writes a JSON Feed to standard output, which can then be consumed by RSS Guard.
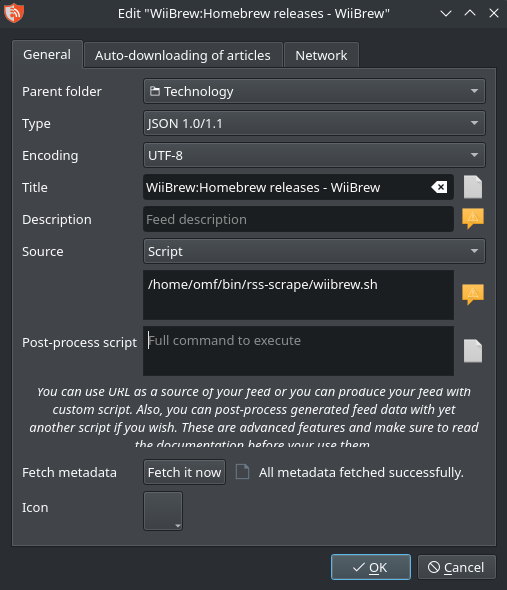
My first use-case for this was to track new Wii homebrew releases. They actually had an RSS feed using "feed43", a service which apparently performed a similar task but was shut down.
That website runs on MediaWiki and doesn’t provide a nice easy CSS selector like #releases, since the HTML is generated from Markdown. The heading for the section of interest does have a #Releases id, but that’s wrapped up in a div which precedes the list items I want, rather than wrapping them:
<h2><span class="mw-headline" id="Releases">Releases</span></h2>
<ul><li><b>7 August 24:</b> <a href="/wiki/Wii-Tac-Toe" title="Wii-Tac-Toe">Wii-Tac-Toe</a> 1.1.0 released by <a href="/wiki/User:Crayon" title="User:Crayon">Crayon</a></li>
<li><b>31 July 24:</b> <a href="/wiki/Seta_GX" title="Seta GX">Seta GX</a> beta 0.2 released by Evoca</li>
<li><b>26 Jul 24:</b> <a href="/wiki/Newo_Bit" title="Newo Bit">Newo Bit</a> 1.0 released by Owen</li>
<li><b>7 Jul 24:</b> <a href="/wiki/Mame4wii" title="Mame4wii">mame4wii</a> 1.35.3 released by Nebiun</li>
<li><b>24 March 24:</b> <a href="/wiki/Shark" title="Shark">Shark</a> 1.1 released by Nebiun</li></ul>After some experimentation, I learned some new CSS selector operators, and was able to extract what I needed with this expression:
document.querySelectorAll('h2:has(#Releases) + ul li')This returns the 5 list items of interest, and is understood by the BeautifulSoup library used by CSS2RSS. All I had to do was make a script wiibrew.sh containing the following:
#!/usr/bin/env bash
set -euo pipefail
curl -s 'https://wiibrew.org/wiki/WiiBrew:Homebrew_releases' | python3 ~/bin/rss-scrape/css2rss.py 'h2:has(#Releases) + ul li'All that remains is to add a new feed with the source type "Script" in RSS Guard: